

Data is the lifeblood of artificial intelligence algorithms. Its reliability, in terms of availability, quality, and robustness, is one of the biggest problems for companies that want to invest in artificial intelligence. How to deal with these problems and set the stage for a successful AI solution?
Identified by Gartner as one of the new technological trends on which companies will invest in the coming years, artificial intelligence begins to be a hot topic.
With a decades-long history of research and development in the academic field, an inspiration for many sci-fi best sellers, AI begins to take hold even in companies. In addition to the growing number of startups that are emerging around artificial intelligence projects in recent years, initiatives on this technology in large companies are also growing.
The implementation of AI was discussed in the first edition of the Artificial Intelligence Observatory of the School of Management of the Politecnico di Milano, held on February 12th.
Internationally, many companies are investing in AI projects, while in Italy, unfortunately, the applications are a bit too little, even compared to other European countries such as Germany and France, but still growing. Most of the artificial intelligence projects in Italy are concentrated in the banking, finance and insurance sectors (17%), automotive (17%), energy (13%), logistics (10%) and telco (10%) industries.
The Observatory’s research has identified eight classes of AI solutions, on which companies are investing most:
- Autonomous vehicle – solutions that support vehicles for transporting people and goods (air, water, and land), means that can interact autonomously with the surrounding environment and implement the behaviors that enable activities for which they are used
- Autonomous Robot – robots able to move within the space, entirely or with parts of them, but also robots that can manipulate objects and interact with the external environment
- Intelligence Object – objects that do not move in the neighboring environment, but they interact with it with sensors. Collecting information with sensors, cameras, and microphones and based on the data collected they are able, through the actuators, to perform some function (from the interaction with the person to systems/systems of the surrounding environment). These include, for example, smart glasses, smart suitcases, video cameras/objects that support everyday life
- Virtual Assistant / Chatbot – software agents that, through natural language, both spoken and written, interact with users of a service; the chatbot can entirely complete the whole process or be just a first contact with the customer
– Recommendation – engines able to analyze information that the client/prospect provides in a conscious or unconscious way during the purchase process, and based on the choices made by the algorithm can suggest alternatives rather than guiding it until the purchase of the product/service being analyzed - Image Processing – an element that mainly involves two different areas, the first to identify objects and people within images, static or sequences, the second is aimed at applications related to the world of biometrics, identification of the face, of the iris or other aspects of the face
- Language Processing – aim is to understand, interacting with the user, through language, some elements, for example, the inflection of language, the emotions that this interaction produces, rather than the ability to rework the info to provide texts or other types of data
- Intelligent data processing – applications that support some specific areas of interest: from predictive analytical tools to tools that monitor physical or virtual control systems, from production plants to different fields, which implement actions in an autonomous way. Examples of Intelligent Data Processing are those applications that support design and product development functions
In the definition of paths of development of AI solutions, the first obstacle that companies have to face is the management of information assets and their data essential for the training and testing of the algorithms.
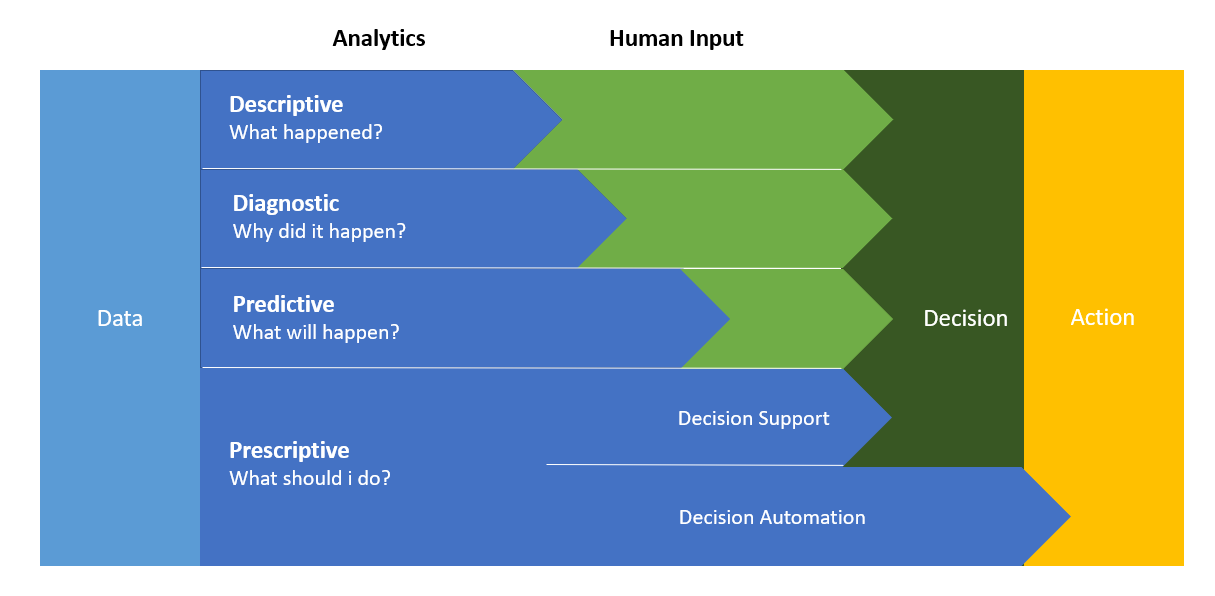
But often companies do not realize the importance of valid data until they have already started their artificial intelligence projects. According to a survey conducted by Forrester last year, only 17% of the companies interviewed are aware of the need to have a well-prepared collection of information before they can activate an artificial intelligence system.
Of the data it is crucial that the company takes care of the availability, completeness, and quality: problems that may arise in these areas would risk derailing the artificial intelligence projects.
Availability
The analysis of data assets forced by the imminent application of the GDPR law has shown that many companies have a heterogeneous and fragmented distribution of data, often historicized in non-connected application silos (for example financial data in a Finance Tool, contacts in CRM , purchase transactions in e-commerce, warehouse data in the ERP, process data in the PLM, etc …)
In the digital age, data tracking systems that companies can rely on to gather information are many and continuously growing. Unstructured data, videos, data coming from social media, connected devices, etc … According to IDC, the global data generation will increase from 16 zettabytes (essentially 16 trillion gigabytes) to 160 zettabytes over the next ten years, with an annual growth of 30%.
To support this process, a robust architectural infrastructure is needed, which allows the collection of consistent, integrated data.
Completeness
The problem of integrity of information is essential to provide the algorithm with a fairly complete dataset to reflect the real world.
Think, for example, of roadmap apps. Google to develop Maps had financed a fleet of cars that drove and digitally mapped each road. Combining digital images with satellite maps and other sources have made possible the development of an application that has now entered into the everyday life of all of us.
Without a complete map dataset and interaction with the satellite, the algorithm would not be able to process the fastest route between two points.
Quality
The quality of the data consists of multiple facets.
Surely a critical aspect for applications of artificial intelligence is to be able to purge the dataset from any bias that reflects any discrimination (race, gender, age, etc …)
Two years ago, the search algorithm of images recognition of Google, which had to censor searches for keywords like “gorillas” and “chimpanzees” because it returned photos of African-Americans, made a scandal.
But data quality also speaks about possible human errors that would negatively affect the decision-making process of the algorithm.
Consider, for example, a customer who lies on own birth date during a registration submission, or the errors of a faulty sensor that one day provides good data and the day after terrible data.
Data quality control thus becomes a crucial practice in the reality that database their decisions and is essential for those investing in artificial intelligence.
This is the case, for example, of KenSci‘s AI platform, which formulates health recommendations for doctors and insurance companies from processing patients’ medical records data.
The system processes millions of medical records from partner organizations around the world. The problem of the quality of the data collected in the medical records is crucial for generating a correct prediction. To overcome this problem, the company has an internal team of doctors dedicated to the quality control of the data generated by artificial intelligence, and in any case, always delegates the final evaluation of the product to the medical uses of the service. In essence, the algorithm submits suggestions to doctors who then have the responsibility to decide independently on how to act.
A good practice to highlight possible errors or fake data is the triangulation of data sources: verifying the data from multiple sources can be associated with the data an index of reliability.
Compliance
The GDPR has also raised a problem of data compliance: data access alone does not guarantee that you can use them as you wish.
Furthermore, the regulation requires that the logic of processing the inferred data must be traced: this involves a significant problem for companies that develop AI applications, which are working on traceability systems capable of generating logical trees that can be understood even by users without technical skills.
How ZeraTech can help you:
Most companies today have to develop their technologies and skills to prepare data for use in artificial intelligence systems.
To security problems (for which it becomes critical to preserving the patrimony of company datasets), architectural (to make the data available quickly and consistently), and data interpretation (essential data sense to implement Data Engineering, Machine Learnings and Business Analytics) are also added the problems of quality control and completeness of information.
We help the CDM (chief data manager) in the development within the company of a Data Intelligence Practices that allows, integrating the structural potential and the interpretative skills, to promote the quality and completeness of the information.
We support and guide the IT departments in making the data transformation and fruition chains more reliable, in choosing the most appropriate data management tools and strategies to enable data so that artificial intelligence initiatives can succeed.
We help in the analysis and definition of the strategic value of the information assets that the company possesses in those realities where there is not yet full awareness of the potential and possibilities of data.




{kind=link}